Python scrapy框架学习笔记及简单实战
工作需要,接触到python的scrapy爬虫框架,据说是python最好用的爬虫框架,没有之一。文章内容为学习过程的笔记,参考资源会贴在文章最后。
安装
win安装
安装pywin32
进入 https://sourceforge.net/projects/pywin32/files/pywin32/ 或者 https://github.com/mhammond/pywin32/releases 下载python对应的pywin32包
傻瓜式安装
检查安装结果,python命令行输入
import win32api,如果没有报错,安装成功
安装Twisted
进入 http://www.lfd.uci.edu/~gohlke/pythonlibs/ ,下载对应twisted和lxml
pip install ******.whl(没有安装pip,[点击查看安装方法][1])输入命令
pip --version检查是否安装成功
安装scrapy
命令行输入:pip install scrapy
scrapy 框架学习
框架架构图
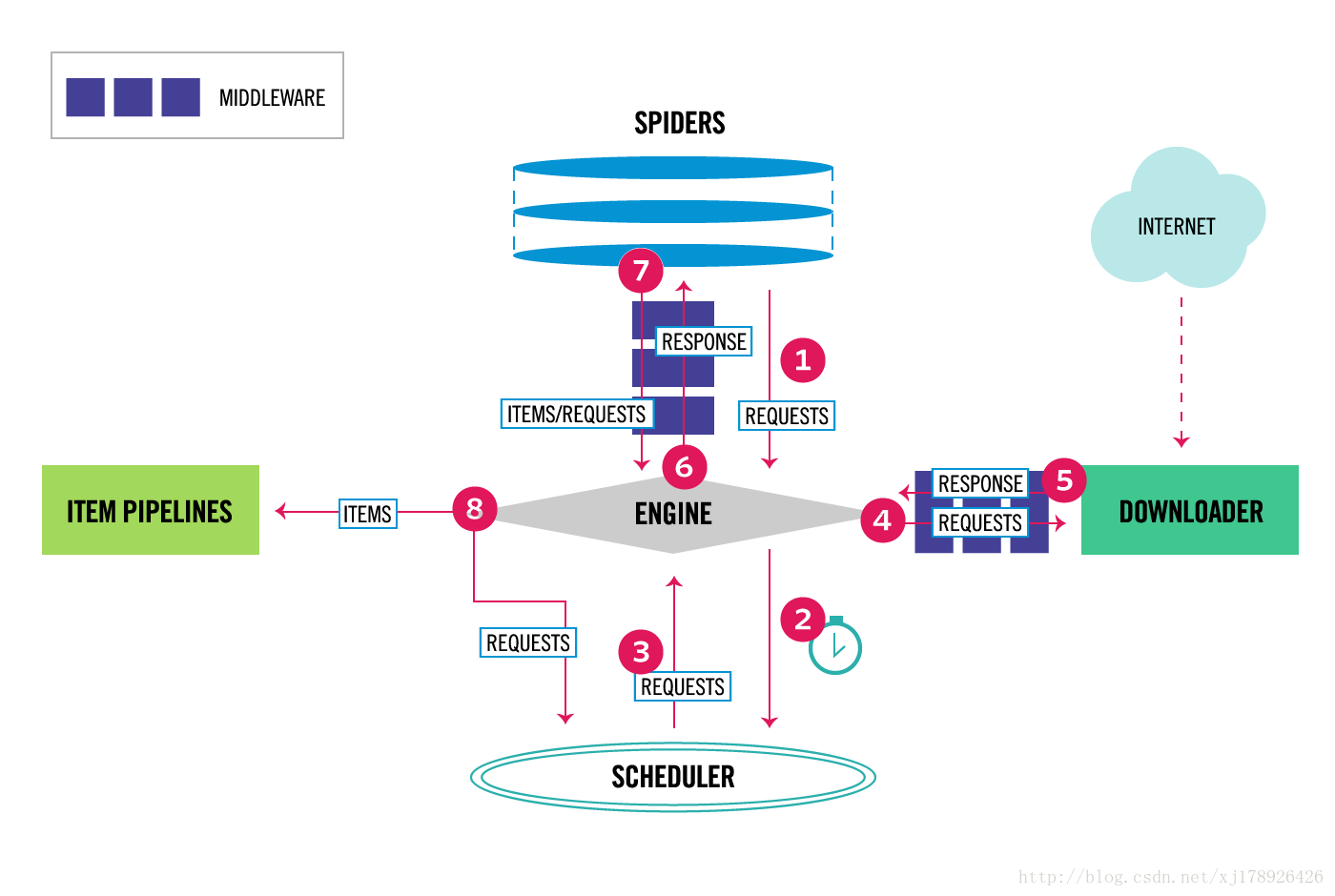
目录结构
items.py 存放爬取的数据模型
middwares.py 中间件
pipelines.py 把爬取的数据保存
settings.py 爬虫的配置信息
scrapy.cfg 项目的配置文件
spiders目录 爬虫脚本
基本使用
1.新建一个项目
2.scrapy.cfg 打包部署文件
3.创建爬虫
4.注意:
爬虫名字不能和项目名字一样
网站域名
5.爬虫文件所在位置
项目名/项目名/spiders/爬虫名字.py
6.查看scrapy有几个类
7.selectors选择器
正则
Xpath表达式
css
8.Xpath表达式规则
demo
9.运行爬虫
10.运行爬虫并保存结果
11.拼接url
12.分页
采取管道方式存储数据
在settings.py中开启
管道中采取json方式纯存储数据,以导入的方式存储
用法:
CrawlSpider
crawlSpider可以创建更灵活的爬虫,可以自定义爬取规则等
创建crawl爬虫
最新请求头地址
http://useragentstring.com/pages/useragentstring.php?typ=browser
设置下载器中间件
1.在middlewares.py增加如下代码:
| |
2.settings.py开启:
并开启下载请求间隔时间
3.爬虫代码
| |
Xpath规则学习
html
Xpath表达式
基本使用
text获取内容
@定位符
表达式
1.获取指定标签的内容
2.根据html属性定位获取内容
@定位符
scrapy配合Xpath
代码示例:(PS:这里的例子为本人的博客,亲测有效:
| |
爬完让我知道了一个事实,我的博客写的并不多,哭/(ㄒoㄒ)/~~
源码地址:
[Python scrapy demo][3]
本文学习资源汇总
- [B站-《Python爬虫框架Scrapy入门, 学会可以直接无视80%的网站!》][4]